

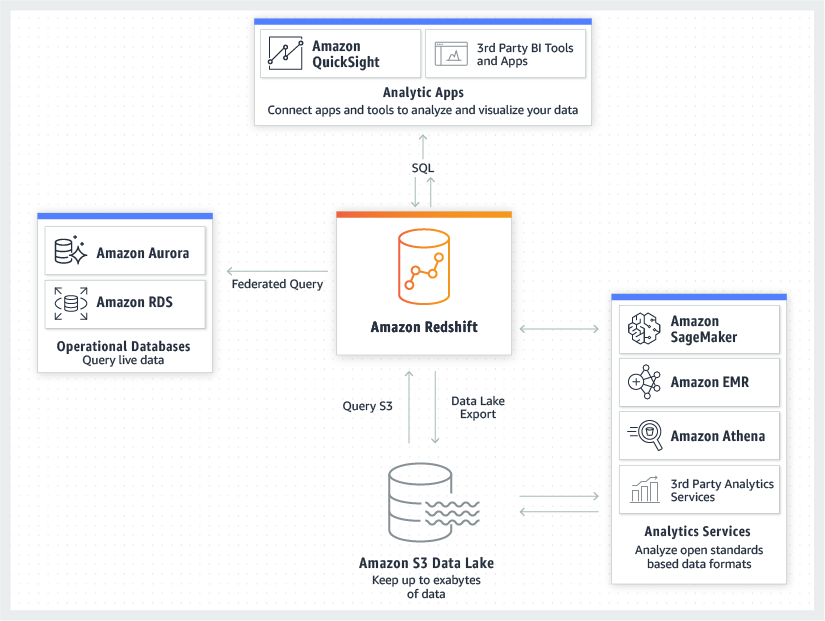
Introduction to Amazon Redshift

Amazon Redshift is a Cloud-based Data Warehouse offered by Amazon as a part of its Cloud Platform, Amazon Web Services (AWS). It integrates with your Data Lakes and can offer up to 3x better price-performance than any other competitor Data Warehouses like Snowflake vs Redshift. Here are a few features of Amazon Redshift that make it an indispensable tool:
Easy to Manage:
Amazon Redshift automates the repetitive maintenance tasks so you can focus on extracting actionable insights from your data instead of being worried about managing your Data Warehouse. You can deploy a new Data Warehouse in just a few clicks using the AWS console. Amazon Redshift then automatically provisions the infrastructure for you. Hence, common administrative tasks like Replication and Backups can be automated easily.
Scalability:
In terms of scalability, Amazon Redshift can scale both users and data pretty quickly. You simply need an API call or a few clicks in the AWS console to change the type or number of nodes in your Data Warehouse. You can scale up or down as your needs change. You can also run queries against petabytes of data in Amazon S3 without having to transform or load any data with the Amazon Redshift Spectrum feature.
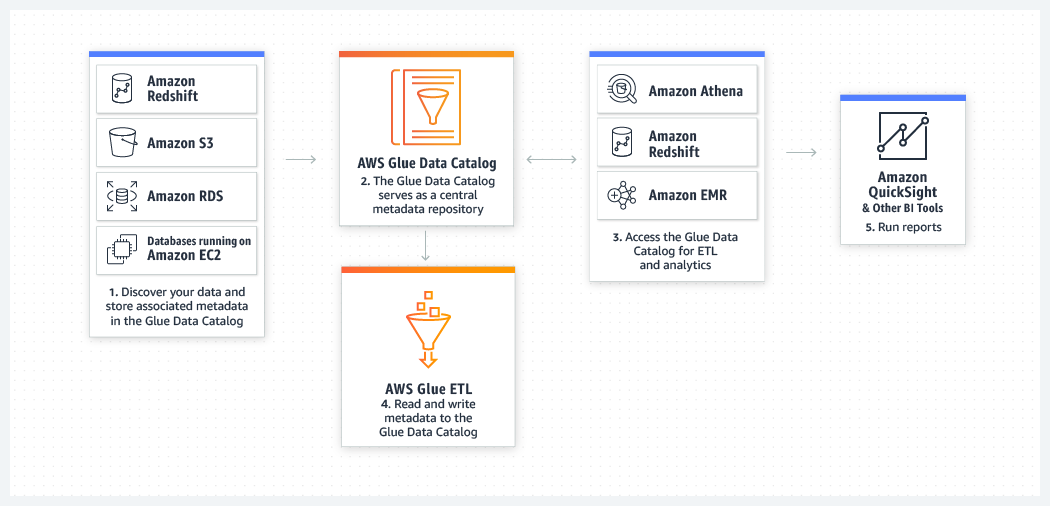
Introduction to AWS Glue

AWS Glue distinguishes itself as a serverless Data Integration service that makes it easy to prepare, discover, and combine data for Machine Learning, Data Analytics, and Application Development workloads. AWS Glue provides you with everything you might need for Data Integration. This allows you to start analyzing your data and putting it to use in minutes instead of months. Here are a few helpful features of AWS Glue:
Data Transformation:
AWS Glue allows you to visually transform data with an intuitive drag-and-drop interface. It also allows you to build complex ETL pipelines using simple job scheduling operations.
Data Discovery:
AWS Glue allows you to discover and search across all your AWS data sets. It also allows you to manage and enforce Schemas for Data Streams.
Understanding the Process of Loading Data from AWS Glue to Amazon Redshift
Here is a list of steps you would have to follow to load the data from AWS Glue to Amazon Redshift:
Step 1: You need to validate the target database engine and version. You also need to create the outbound security group for the target and source databases.
Step 2: Next, you need to launch the Amazon Redshift Cluster and create the database user for the migration in the cluster. You also need to create the Access Management (IAM) service role and the AWS Identity for the Cluster. Give it read access to the Amazon S3 bucket data source. Attach the role from the previous step to the target database and review the different settings.
Step 3: Add a new database in AWS Glue and a new table in this database. Provide the Amazon S3 data source location and table column details for parameters then create a new job in AWS Glue. Next, Choose the IAM service role, Amazon S3 data source, data store (choose JDBC), and “Create Tables in Your Data Target” option. After selecting the connection endpoint of the Amazon Redshift Cluster, save and run the job in AWS Glue.
Step 4: Delete the job in AWS Glue when the use case is complete.
Conclusion
This blog talks about the basics of AWS Glue and Amazon Redshift and the steps involved in migrating data to Amazon Redshift using AWS Glue.
Hevo offers a faster way to move data from Databases, SaaS applications, etc., into your Data Warehouse to be visualized in a BI tool. Hevo is fully automated and hence does not require you to code. You can try Hevo for free by signing up for a 14-day free trial. You can also have a look at the unbeatable pricing that will help you choose the right plan for your business needs.
Follow Techdee for more!


{kind=link}